Sistema de Recomendación de Películas
1. Configuración del Ambiente
Para empezar, se puede utilizar un entorno virtual como
Google Colaboratory o un editor de Python local, asegurando
que Python 3.x esté instalado. Es necesario importar
librerías esenciales como Pandas,
NumPy, y de Scikit-learn: TfidfVectorizer y
NearestNeighbors.
!python -V print('------') !pip show Pandas | grep 'Name\\|Version' print('------') !pip show Matplotlib | grep 'Name\\|Version'
2. Obtención y Tratamiento de Datos
Se cargan los archivos CSV (`movies` y `ratings`) en DataFrames de Pandas. El preprocesamiento incluye:
- Eliminación de nulos y duplicados.
-
Creación de nuevas columnas:
content(a partir de géneros) ygenre_set(un conjunto de géneros). - Asegurar los tipos de datos correctos para cada columna.
3. Análisis Exploratorio (EDA)
Una vez limpios los datos, se realiza un análisis
exploratorio para entender su estructura y distribución.
Esto incluye la inspección de atributos con métodos como
info() y describe(), y la
creación de visualizaciones (histogramas, boxplots) para
validar la calidad de los datos antes de pasar al modelado.
A continuación, se muestran algunas de las visualizaciones generadas durante el Análisis Exploratorio de Datos:
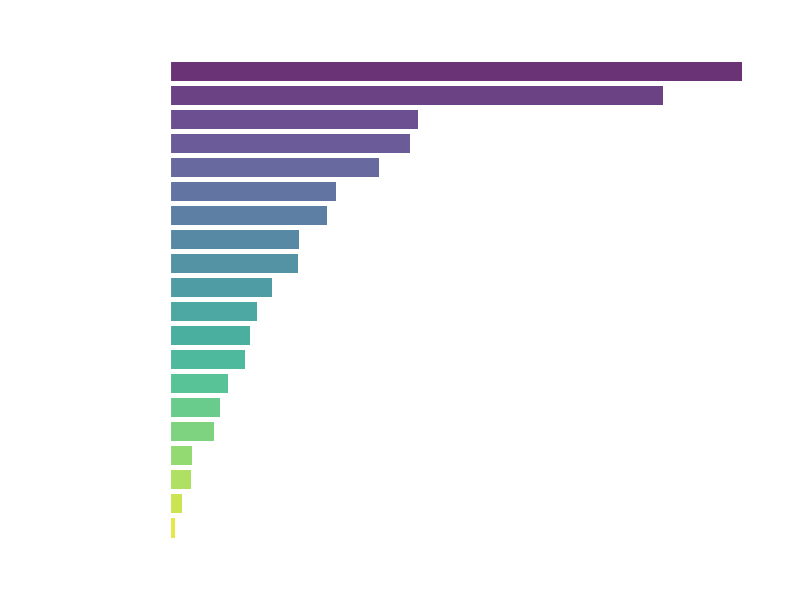
Distribución de géneros.
4. Recomendación no Personalizada (Ranking Bayesiano)
Para crear un ranking justo de películas populares, se utiliza un promedio ponderado bayesiano. Esta técnica evita que películas con pocas calificaciones altas superen a aquellas con muchas calificaciones consistentemente buenas. La fórmula es:
$$ WR = \left( \frac{v}{v+m} \right) R + \left( \frac{m}{v+m} \right) C $$
- WR : Calificación ponderada.
- v: número de votos para la película.
- m: mínimo de votos requeridos.
- R: calificación promedio de la película.
- C: calificación promedio de todas las películas.
5. Recomendación Personalizada (Basada en Contenido)
Se implementan dos estrategias basadas en el contenido de las películas:
- Similitud de Jaccard: Compara los conjuntos de géneros entre películas para encontrar las más similares.
-
$$ J(A, B) = \large \frac{|A \cap B|}{|A \cup B|} $$
Similitud de Coseno con TF-IDF:$$\text{Similitud del coseno} = \cos(\theta) = \frac{\mathbf{A} \cdot \mathbf{B}}{\|\mathbf{A}\| \|\mathbf{B}\|}$$
-
Se calcula la matriz TF-IDF para la columna
contentde las películas usandoTfidfVectorizer. Esto convierte el texto en vectores numéricos que representan la importancia de cada palabra. -
Luego, se calcula la matriz de similitud del coseno
(
cosine_sim) a partir de la matriz TF-IDF para encontrar la similitud entre todas las películas. - Se crea una función que, dado un
movieId, encuentra las películas más similares basándose en esta matriz.
-
Se calcula la matriz TF-IDF para la columna
# Ejemplo con Similitud de Coseno tfidf_matrix = tfidf_vectorizer.fit_transform(df_movies['content']) cosine_sim = cosine_similarity(tfidf_matrix, tfidf_matrix)
6. Recomendación Personalizada (Filtrado Colaborativo)
Se utiliza el algoritmo K-Nearest Neighbors (KNN) para encontrar usuarios con gustos similares.
Distancia del Coseno:
Al igual que en TF-IDF, la métrica que el modelo NearestNeighbors utiliza, en este caso minimiza y se calcula como:
$$ \text{Distancia} = 1 - \text{Similitud} $$
Una menor distancia implica una mayor similitud. En este contexto, los vectores $\mathbf{A}$ y $\mathbf{B}$ son las filas de la matriz de calificaciones, representando los gustos de cada usuario.
- Se crea una matriz con usuarios como filas y películas como columnas, y se normalizan las calificaciones.
-
Se entrena un modelo
NearestNeighborscon la métrica de similitud del coseno. - Para un usuario dado, el modelo encuentra los 'k' vecinos más cercanos (usuarios más similares).
- Se recomiendan las películas que a estos vecinos les gustaron y que el usuario original aún no ha visto.